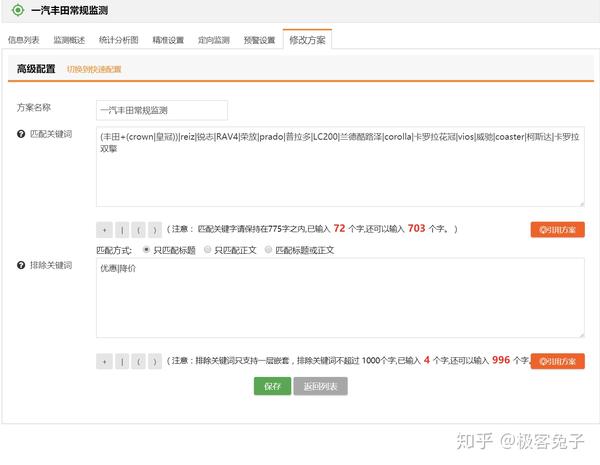
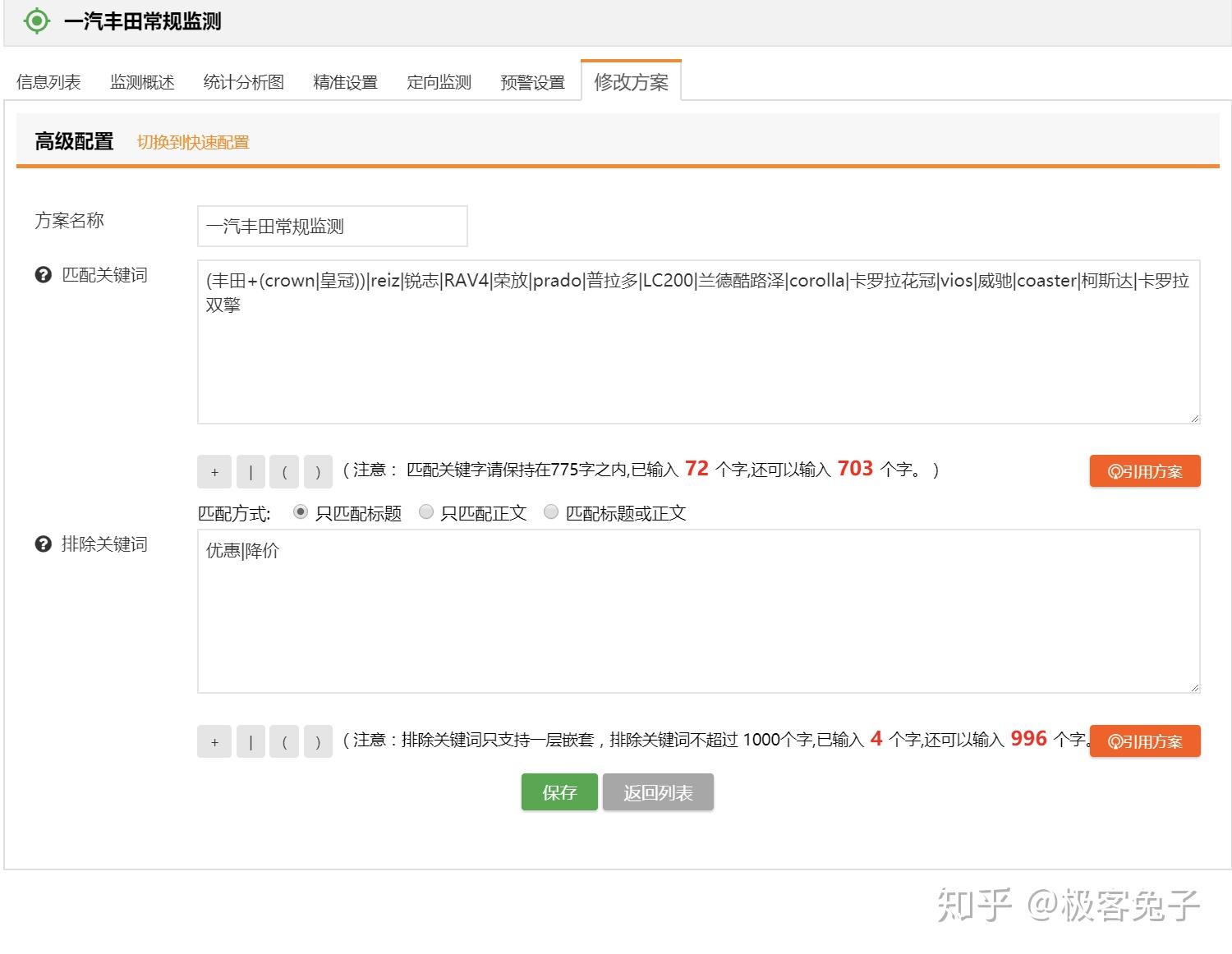
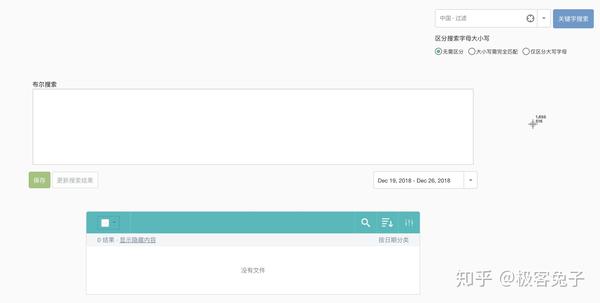
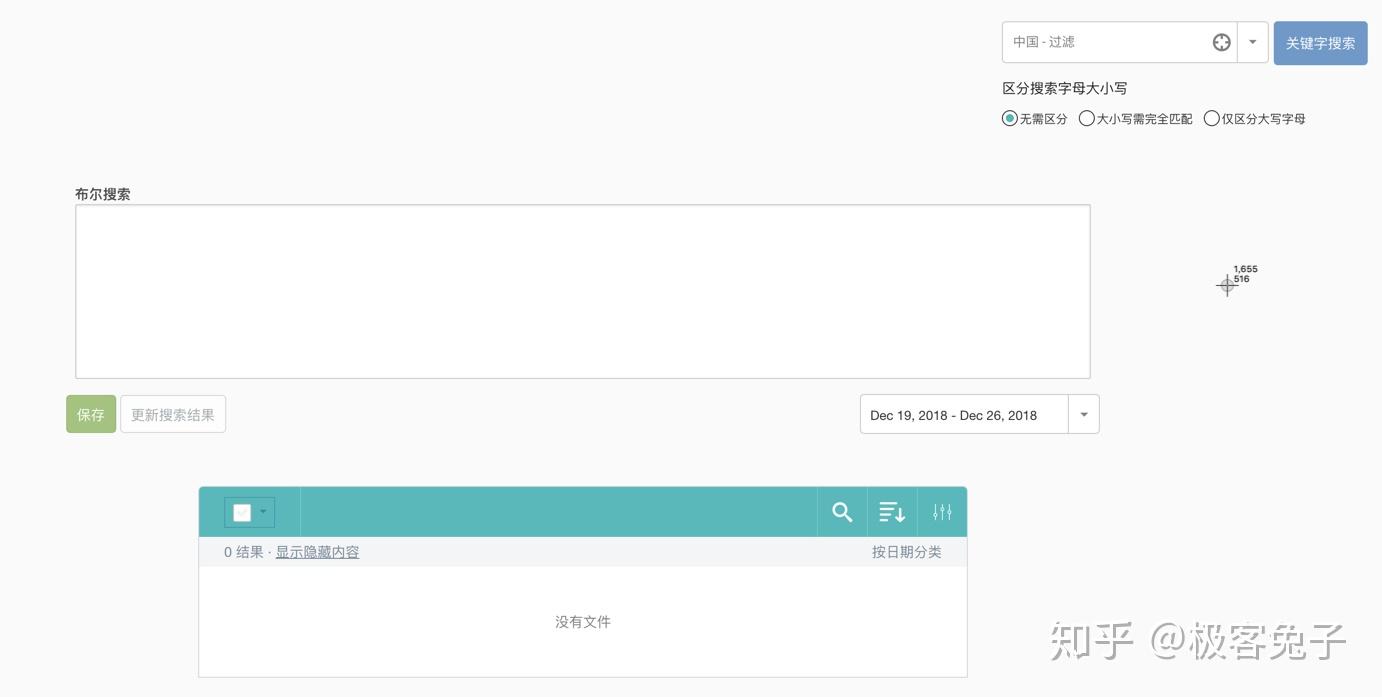
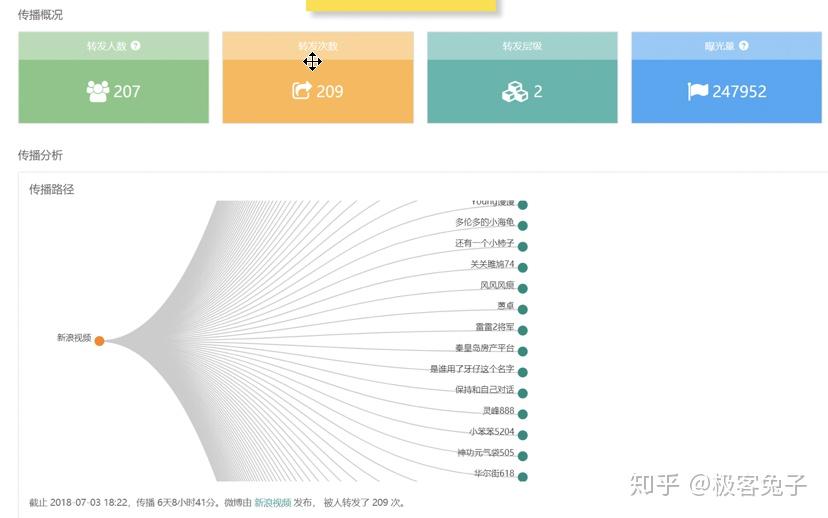
2018年我接触了很多舆情公司,主要原因还是因为想合作拿单或者代理他们的产品,也正因为如此,对一些基础功能和数据情况的对比感受会更明显,到了年底最后几天了,着手一些总结性的文章,于是就写出了本文。 首先舆情产品的狭义,大体来说是基于舆论情报的分析,提供决策支持。其中舆论的部分比较重,因为传统舆情产品主要是对网络舆论的监测、预警、报告三项核心服务。如果说广义的舆情,其实就是情报,从网络的任何细小角落里发现蛛丝马迹,推导出可以提供决策支持的信息、情报、知识、结论等等。 所以,如果单指传统舆情产品,大都包含以下核心功能: 今年,传统舆情产品大都开始加入了一些更细致的功能,一方面是因为传统产品同质化情况过于严重,另一方面也是因为现阶段如果只做政府舆情已经市场比较饱和了,但是突破到企业市场的时候,就不是这么简单了。首先企业对舆情的本质需求偏低,这里通常细分成口碑舆情、品牌舆情、高管舆情等,也就是说只有部分有实力的公司愿意购买舆情系统,一般公司很可能不愿意付出多少代价来采购舆情系统。而且很多公关公司包揽了舆情产品的功能及作用,所以如果真要说的话,那就是所有的公司大都只想买个服务,并不是非要买个系统然后自己的运营人员还得学习怎么用。 那么问题就来了,既然买的是服务,服务的可能性是远大于舆情系统自身的,服务里面有人工的作用,所以人工可以判断一些情况,包括报告、预警、引导处置等等。但是舆情系统则需要负责的设定,包括关键词组合、预警条件组合、引导处置语料配置等等。这些设置的繁琐程度,如果是没接触过舆情系统的,尤其是“懒惰”的体系内人员的话,估计只有甩脸和骂街的份,只有积累了一定规则和词库的组织才能比较好的用起来,否则大都需要商务、运营人员介入帮助客户来配置。 为什么舆情系统的配置一直是大家诟病而且更倾向于买个服务“全包”呢?这就要从关键词规则配置说起了,目前市面上大多数系统都有一些通用的配置方法,比如: 上图是凡闻的方法,基本策略是,包含全部(and关系),包含任意(or关系)和排除(not,and关系),也就是说(a and b and c) and (d or e or f) not (g and h and i),但是这样的配置实际上是一个非常简化的配制方法,很多细项功能是无法实现的。 上图是舆情通的方案配置方法,第一层是匹配,第二层是排除,每个都支持基础布尔表达式,包括:括号、与(+号,表示and)、或(|号,表示or),这样就可以做一些更复杂的组合。同时这里允许选择该表达式生效区域是标题还是正文还是全部。 上图是Meltwater的高阶布尔表达式搜索框,关键词配置监测任务也是一样的操作。这个布尔表达式的检索逻辑以及可控制的维度可以说是比较全面的,其他公司的基本类似,包括百分点舆情、智慧星光、清博舆情、慧科等等,大都只是他们的变种或者增加了一些维度,殊途同归。这个布尔表达式可以多复杂呢?见下图说明。 也就是说,Meltwater的布尔表达式不仅具备了与或非关系,还支持标题匹配、逻辑顺序、模糊匹配、位置关系等细分功能。但是看到这么多配置方法,再加上舆情中可能出现的词千变万化,每次检索出来的数据还要大海捞针找到有价值的线索,这种工作实在不是一般人能享受过程的,所以所有市面上的舆情系统都无时不刻的在被诟病。 近年来,舆情公司应对这种客户的诟病的方法不外乎几种,一,由公司安排运营人员、商务人员协助配置甚至直接帮助配置关键词规则;二,直接购买服务,全部操作都由运营人员操作,客户只需要提出需求便可。至于简化配置方法的第三条路,也就是规则库或者词库一直因为客户的跨行业、跨地域区别太大,导致停留在摸索期。积累了大量用户操作行为之后,一些公司已经开始将词库进行模型训练并建立基于深度学习技术的文本分类模型,用于舆情的下一代功能改进,比如某公司舆情分类模型已经至少可以看到二级,且覆盖较全面。 我个人认为以后可以预见到,关键词配置会进入辅助阶段,而已经训练好的模型会进入主流,只要勾选便可以直接使用,并且还可以通过用户行为不停地优化,最终甚至引入更复杂的推荐引擎,将找到线索的可能性以及用户体验大幅度改进。这也是2018年舆情系统的一个重要的改进方向。 另一个比较重要的舆情系统改进方向是加强了监测类型,传统监测类型是关键词自定义监测任务、专题监测任务、事件监测任务,现在则是开始加入更精细化的人物监测任务、传播监测任务等等。 人物监测一直是一个老生常谈的监测类型,一方面因为涉及个人,有一定的隐私问题,所以尽可能不跨越那条线,主要面对公众知名人物的正面形象问题进行把控。另一方面人物监测的方法一直是一个头疼的事情,首先人名是不靠谱的,重名可能性很高;其次是人作为一个实体,具备很多属性,包括出生地、居住地、现时活跃地都可能不同,职位可以有多个,身份也可以有多个,别名和昵称都可以有多个,这是互联网的天然优势所在,但是导致的结果就是监测的时候会比较麻烦,准确率和召回率都会成为问题。解决方案就是通过NLP,对每个文章中的人名识别,人名最近距离的描述句法进行识别,找出描述词-分析词性-识别组织机构、职位-企业库内验证,最终识别出要监测的人物对象是否在这篇文章中,是否是本文的主要内容主体等等。通过这一系列的技术手段,才可能让人物监测变的准确“那么一点点”,而人物的别名库的引入,会让召回率尽可能提高一些。双剑合璧,才能让人物监测变的更好用,但是说实话,考虑到非规范文章中对人物的描述信息极为缺失,人物监测在政府舆情监测上肯定不会是一项好用的功能。因为首先这是大海捞针,舆情一般不会直接出现在新闻稿中,大都是在社交平台上滋生和蔓延,引起注意后才开始新闻稿件(这个主要是针对政府,因为一般新闻组织不会没事乱发针对政府的负面新闻,大都是要审阅核实一下的)。那也就是说即使系统识别准确了,每天可能有大量关于某人的文章被发现了,即使情感分析判断了一遍,也很难说工作就结束了。人判断的因素一直存在,因为人是在做决策,系统的用户看到了大量信息,筛选出可能会被领导注意的部分,领导再次进行决策,找出最符合该组织利益影响点的信息,决定是否需要处置。几次筛选过程很受人的主观因素影响,所以机器无法轻易替代,只能是个辅助。于是就产生了问题,每次筛选都会有信息丢失,丢失的信息是否有价值后续的决策人员是不知道的,而不筛选的话,大量信息又无法一一审查,每日工作量都会变得很大。所以这里就会形成一个悖论,召回率越高,数据量越大,又需要进一步筛选,未来AI技术会在这部分尽可能降低人工的繁琐性识别工作。 还有一个在18年被重视并强化的功能是传播链分析,实际情况是通过持续采集数据,分析某篇文章传播链条或者某个事件的传播轨迹。包括原创、转载、转发、阅读和点赞等情况。如果数据覆盖范围够大,数据量够多的系统,可以生成树状或者网状传播图。 例如上图(百分点舆情),虽然这个样例中只有一层传播,所以没法看出是一个树状结构。不过如果是分析某篇热门文章的时候,就变成了一个从中心放射出的圆形网状结构了。这种传播链条分析对数据要求比较高,不仅要识别出文章自身,还要识别文章变种,相似相关等等,最重要的是,字段中还要识别出原创和转载。当然这里面有一些套路和技术策略,我就不多说了,属于业界技术小秘密。 以上就是我对2018年舆情产品的一些理解和认知。我是兔哥,舆情和公安大数据行业出身,后续主攻企业多维度数据分析和挖掘。我在知识星球上有免费和收费群,欢迎搜索“兔哥数据星球付费群”、“兔哥的数据星球免费群”,其他事宜可以知乎私信联系我。